Infrastructure as Code
For my master's degree thesis I did research about infrastructure automation with configuration management software. I discovered the power and advantages of these tools and would like to share my findings about Infrastructure as Code with my readers. During my research I had the chance to meet Patrick Debois, who seems to be master Yoda of the DevOps community, while I am still a young Padawan. His talks definitely influenced my thesis and probably even this post.
The availability of "infinite" compute power with virtual server technologies combined with a new generation of web frameworks lead to a new world of scaling problems, boosted by the launch of Amazon Elastic Compute Cloud (EC2) in 2006. Flexible software development methodologies such as Continuous Integration, lead to faster release cycles and makes the work of the Operations manager or Release coordinator a lot harder. He has to make sure these releases are correctly deployed onto the production environment. It is important that not only the software itself is tested, but also the behavior on this environment.
All of these changes led to a new breed of configuration management tools for automating the infrastructure. These tools use the Infrastructure as Code paradigm, that models your infrastructure in code, by breaking it down into components that interact with each other. In this context, Infrastructure isn’t anything physical (or virtualized) like servers or networks, but is the collection of components that are used to deliver your service or product to the end-user: configuration files, software packages, user accounts, processes, ...
Every component type is abstracted just like an abstract class, that allows you describe the end-state of instances of that type. For example, a software package object will have an install, upgrade and remove method. This means administrators do not have to worry about specific implementation details anymore, and can now focus on the functionality and cooperation of abstracted components. A blueprint is designed that will be executed by a provider on the actual device. The provider takes care of the method's implementation and will translate operations to commands for the underlying operating system. The code becomes operating system independent; a provider for a Debian operating system will translate the install method of a software package to the apt-get command, and one for CentOS will translate it to the yum command.
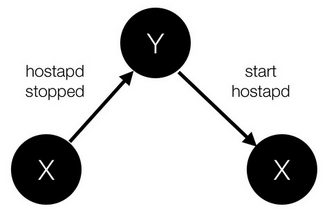
All the method implementations are idempotent, which means that they can be applied multiple times without changing the result beyond the initial application. If you would execute the install method of a software package multiple times, it would only be installed once. These idempotent operations allow a non-optimal execution order, whereby the desired system end-state is reached by convergence.
Periodically running these idempotent operations results in auditing; if for some reason, a component deviates from it's described end-state, the code will restore the component (and the system).
Because the infrastructure is modeled in code, we can use the same tools and principles as we would in modern software development. Using Version Control Systems like git, we introduce versions of the infrastructure that can be maintained alongside the application code. If a new unstable version breaks something, the infrastructure can be reverted to a previous stable version. You can also easily spin up an exact (virtual) duplicate of your production server to test your software application before deploying it.
git log d1b89d90ec07e08697acada12cec79f3b812e01c Updated ruby version 9256488f721eccdc245059edb9ff9b2b51aea24b Added SSL to nginx template 9b72807027f96bbbb929207b5bd8a92becfeb889 Install MariaDB and PhpMyAdmin 5f56e2e4580a274b4f018d75f3d124a48a5b0f1d Added php5-cli to installed packages
By describing all components and their interaction with each other, your whole infrastructure becomes documented. This is especially useful when multiple people are involved in the management of the infrastructure.
The tools

The big three of open-source configuration management software/tools are CFEngine, Puppet and Chef. The answer to "which tool should I use?" is actually "yes". A lot of blogs compare these tools and suggest you to use one of them based on a likely outdated argument, but in reality, it is not important which tool you use, as long as you use one. The main competitor of any of these tools remain the in-house created bash scripts. Maintaining all of these scripts for every combination of role, hardware and operating system is such a time consuming task, and these tools will make your work so much easier.
The main advice I would give anyone that wants to look into these tools would be to go for either Puppet or Chef. The open-source version of CFEngine feels more like a framework than a fully featured tool. In the end, I went for Chef because it met the requirements of my use-case, but it is possible that I will give Puppet a second try in the near future.